Use Case: AI-generated synthetic time series data
This guide provides the step-by-step procedures for AI-generated synthetic sequence data.
Last updated
This guide provides the step-by-step procedures for AI-generated synthetic sequence data.
Last updated
Assuming a customer has two tables with time series data, "Patients" and "Medications," which need synthesis. These tables, simulating medical data, will be synthesized, considering "Medications" contains time series data and there's a foreign key-primary key relationship (one-to-many) between them.
For prerequisites check Prerequisites or watch the video below.
Initially, data from these tables are extracted from the customer's database in .csv format. An overview of the first few columns for both "Patients" and "Medications" tables is provided.
The process involves storing these tables in a database linked to Syntho. This database, referred to as the source, is where the data originates. Syntho then synthesizes this data and transfers it to another database, known as the destination. In this example, a MySQL database and MySQL Workbench are used to create both source and destination databases, and to upload the "Patients" and "Medications" tables to the source. Subsequently, a new workspace in the Syntho app is created and connected to these databases.
To integrate the tables into the new database, first, create the source schema for our tables.
Ensure the schema is accurately named; our new schema is titled "healthcare."
Once the "healthcare" schema is created, the tables remain empty, necessitating the next step: table creation.
Reviewing our original .csv data, the "Patients" table comprises the following columns:
Id, BIRTHDATE, DEATHDATE, SSN, DRIVERS, PASSPORT, PREFIX, FIRST, LAST, SUFFIX, MAIDEN, MARITAL, RACE, ETHNICITY, GENDER, BIRTHPLACE, ADDRESS, CITY, STATE, COUNTY, ZIP, LAT, LON, HEALTHCARE_EXPENSES, HEALTHCARE_COVERAGE.
Thus, we must establish 25 columns with precise values. Below, an SQL script is provided to facilitate the creation of the "Patients" table, a process similarly applied to the "Medications" table.
Creation of "Patients" table can be found below.
As you can see in the below images, the tables are ready.
The tables are now prepared for data insertion. The following MySQL script will populate the "patients" table with data from the patients.csv file.
To reconcile date format discrepancies between the CSV file (DD/MM/YYYY) and MySQL's expected format (YYYY-MM-DD), the last four lines of the script adjust the date formatting. This adjustment prevents MySQL from defaulting unrecognized dates to '0000-00-00', utilizing the STR_TO_DATE function for conversion during import. Subsequently, the "patients" table will be populated.
The "patients" table now contains 12,352 rows.
The "patients" table now contains 12,352 rows.
This procedure will be similarly applied to the "medications" table.
Towards the end of preprocessing, empty schema and tables for the target destination will be established, mirroring the healthcare schema creation process. However, adjustments are made to specify the healthcare_synthetic schema.
With the tables set for the synthetic schema, the database is ready. The next step involves creating a workspace in Syntho. For workspace creation, refer to the Syntho documentation or follow the provided steps, ensuring the MySQL database connection details are accurately filled. Successful connection testing, indicated by a green circle, will be required for both the source and destination databases.
Finally, primary keys and foreign keys are defined in the database. In our example, "PATIENT" column of medications table is a foreign key and connected to the "Id" column of patients table where "Id" is a primary key of patients table.
medications.PATIENT
patients.Id
Our database is now ready. Next, we'll open Syntho to create a workspace. For detailed instructions on creating a workspace in Syntho, please consult the Create a workspace section in the Syntho documentation. To create a new workspace, you have two options:
On the Launch Your Workspace screen, select Connect to a Database.
Use the left toolbar to navigate to Create workspace > From database > [Database].
Ensure you fill in the required fields accurately to establish a connection with the MySQL database. After entering the information, click on "Test Connection" to verify the connection. A green circle indicates a successful connection. This verification process applies to both the source and destination databases.
Your workspace is now prepared for use.
For AI-powered synthetic data generation, ensure your data is fit to synthesize. Syntho is capable of processing data in the form of lists, sequences, or time-series when structured in entity table-linked table structure. Ensure your data satisfies the following:
The structure is tailored for handling lists, sequences, or time-series data.
It includes two tables:
an entity table that satisfies the Entity tables requirements.
a linked table.
Each record in the entity table needs a unique ID (primary key).
Each record in the linked table must reference the unique ID from the entity table (foreign key).
Similar to the requirements for Entity tables, eliminate columns whose values are directly derived from other columns.
Remove row values that are derived directly from values in other rows. For instance, if your dataset includes sequences with start_date and end_date columns, and each start_date matches the end_date of the row before it, remove one of these redundant values, understart_date or end_date.
For more information on preparing your data when synthesizing complex table relationships see: Sequence model.
Our example table fully meets these criteria.
Under Column settings > Generation Method, select AI-powered generator for Syntho's ML models to synthesize data.
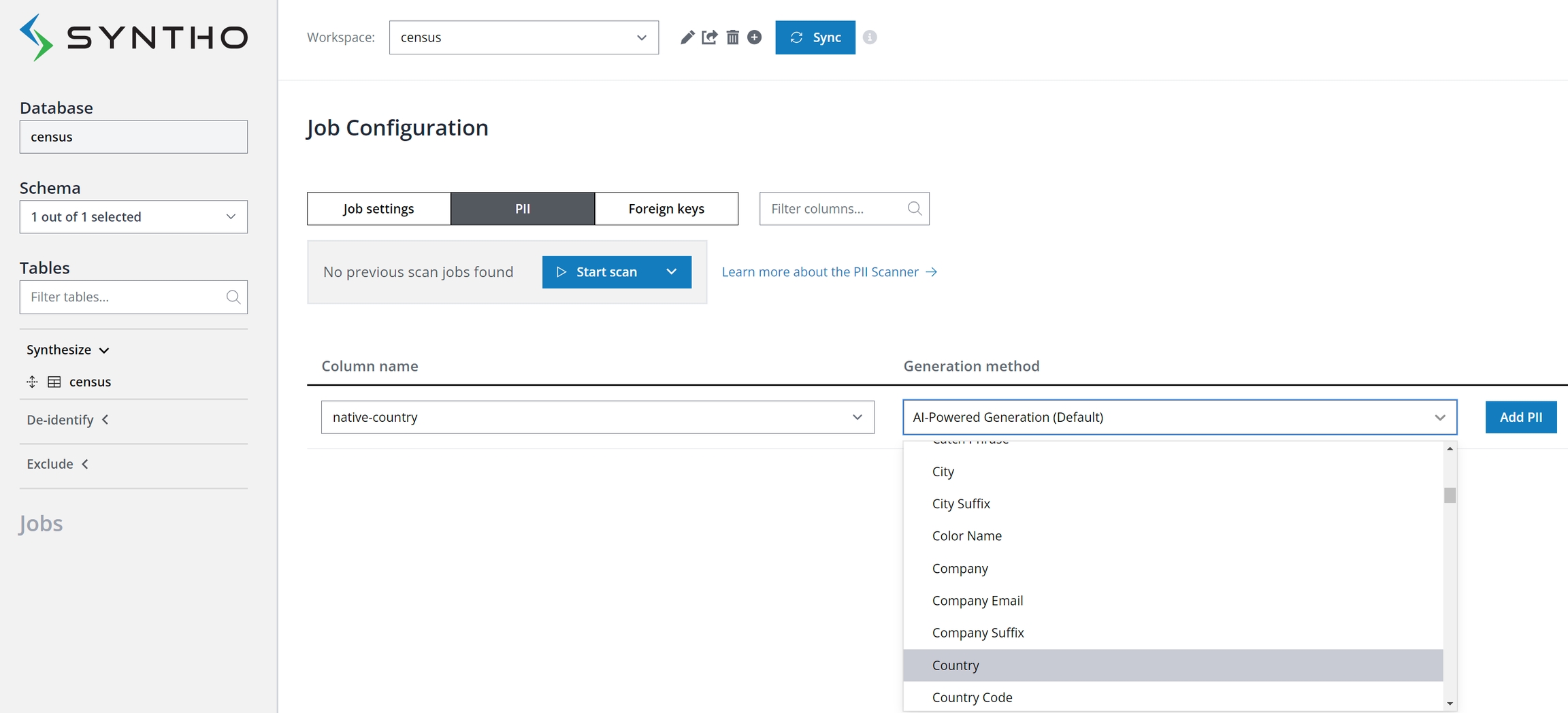
In the PII tab, you can add new columns to the list of PII columns, either manually or by using Syntho's PII scanner. You have the option to manually label columns containing PII by selecting the column name and optionally choosing a mocker to apply. Clicking "Confirm" will mark the column as containing PII and confirm the mocker selection.
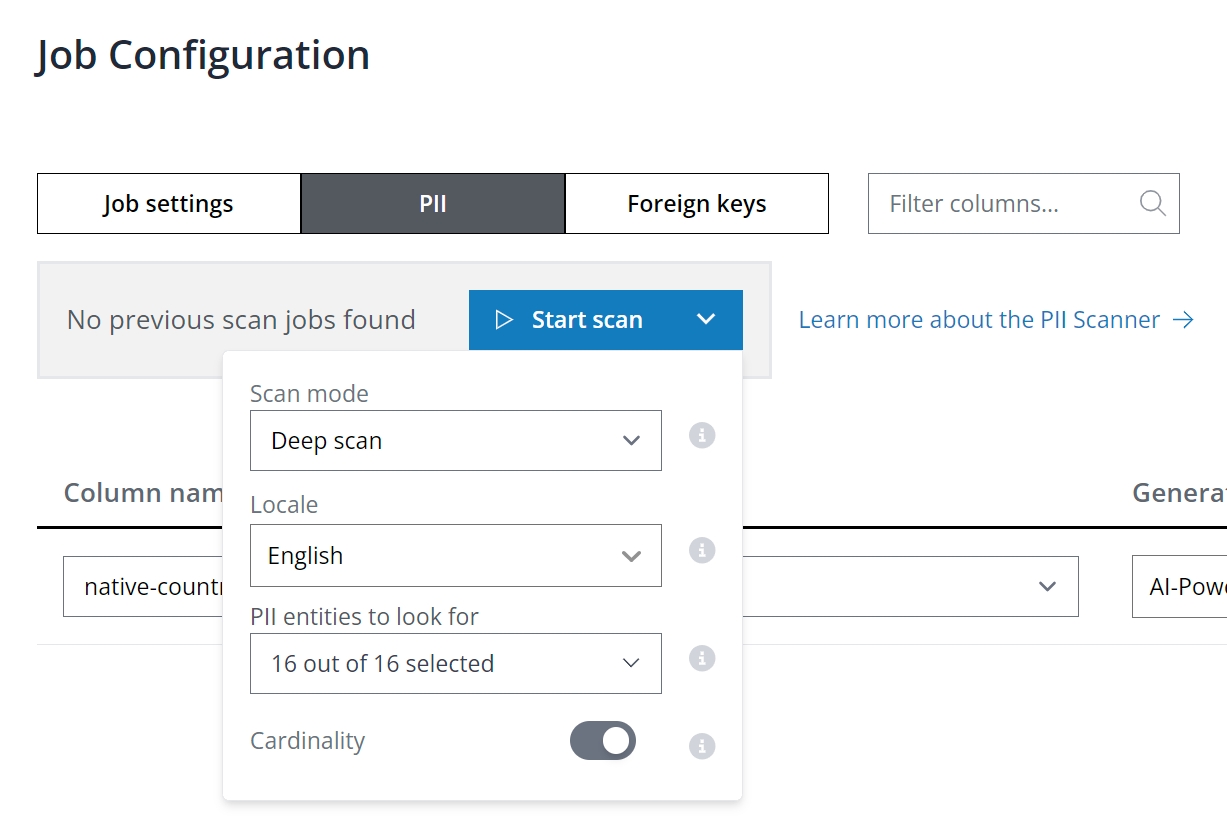
Alternatively, deploy automatic PII discovery with the PII scanner. Launch a scan to detect PII across all database columns from the PII tab in the Job Configuration panel. Note that the scanner offers both Shallow and Deep scan modes:
The shallow scan assesses columns using regular expression rules to identify PII, optimized for speed but with variable accuracy.
The deep scan examines both metadata and data within columns for a thorough PII identification.
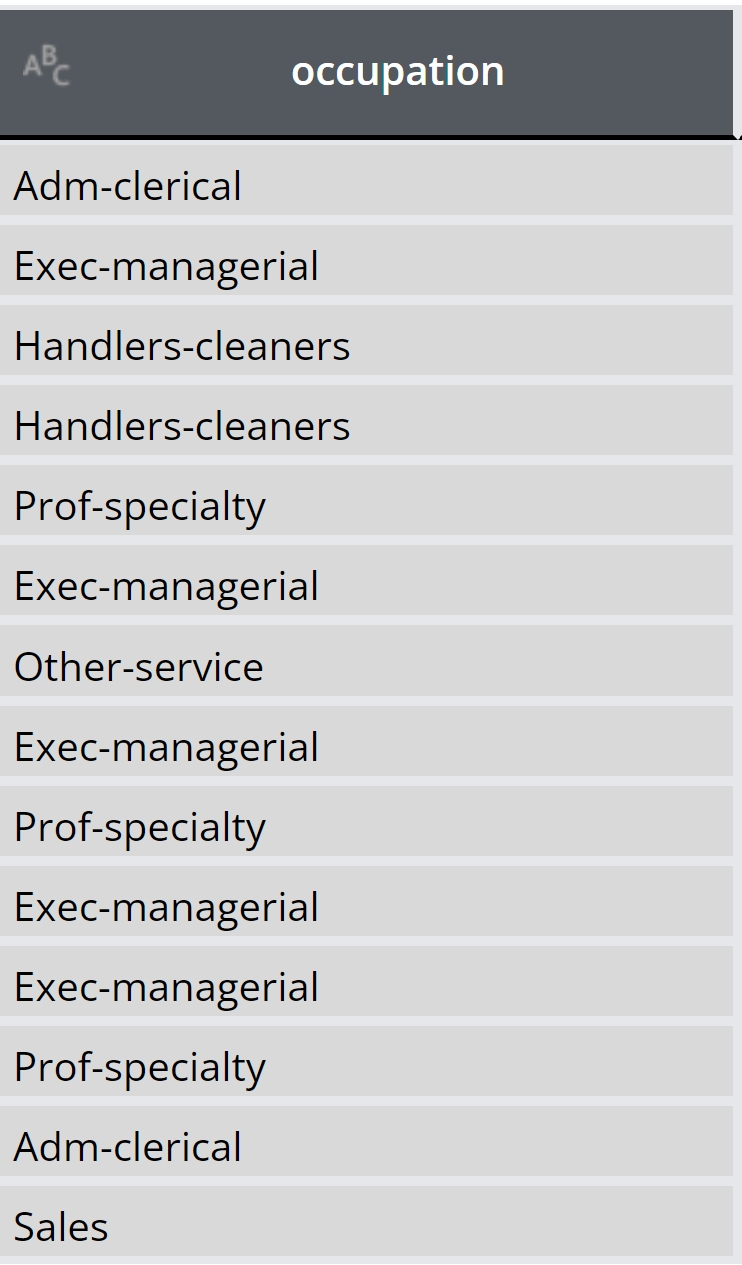
This feature helps hide sensitive or rare observations, like specific occupations in the "census" table, by replacing them with a user-defined value, enhancing data privacy. Adjust the rare category protection threshold and replacement value in Column settings > Encoding type > Advanced settings.
Rare category protection threshold: All column values that occur as frequently or less than the rare category protection threshold are automatically replaced.
Rare category replacement value: All column values that occur as frequently or less than the rare category protection threshold are automatically replaced by this replacement value.
For example, occupations appearing as frequently or less than 15, will be replaced with the sign asterisk or “*”. The number and sign is voluntarily and can be defined per user request (See below illustration).
Select Advanced settings under Encoding type to view and adjust settings on the column-level.
You can adjust the following advanced column settings, depending on the selected encoding type:
Discrete | Continuous | Datetime
Clipping threshold: The floor and ceiling of a column as the Nth lowest and highest value, where N is the clipping threshold. The threshold value will process the values as not to exceed the ceiling and floor.
In the job settings, under table settings, you can adjust generator-level settings, including the maximum number of rows for training to optimize speed. Leaving this setting as None utilizes all rows. The "Take random sample" option allows for sampling:
On: Random rows are selected for training.
Off: Top rows as per the database are used.
Let's consider the Patients and PatientMedications tables shown below. They are from Syntho documentation and resembles our patient and medications tables. Here, the Patients table is the entity table. The PatientMedications tables is the linked table.
To synthesize these tables using Syntho's sequence models:
Syntho starts by synthesizing the Patients table.
Then, it synthesizes the PatientMedications table using the synthetic Patients table as context.
To use Syntho's synthetic data sequence models, you can do the following:
Choose Sequence table model under Table mode in Advanced Settings.
On the Job configuration panel, select Generate.
Finally, select Start generating.
Before initiating the generation process, you have the option to modify sequence model parameters. Here's an overview:
Max sequence length: Sets a cap on sequence lengths, truncating any sequence that exceeds this limit.
Rare long sequence protection threshold: Defines a limit for the length of data sequences used in training, adjusting the longest sequences to the length of the Nth sequence.
N generated entities: Determines the number of entities to generate, each associated with a sequence.
Read batch size: The quantity of rows read from each source table per batch.
Write batch size: The quantity of rows inserted into each destination table per batch.
N connections: Specifies the number of connections.
Users are required to manually TRUNCATE their tables in the DESTINATION database before initiating each new data generation job. If truncation is hindered due to existing constraints, these constraints should be temporarily disabled before truncation and then re-enabled afterwards. For instance, to facilitate the truncation process when foreign key constraints prevent it, use the following SQL commands: First, disable the constraints by executing SET FOREIGN_KEY_CHECKS = 0;, then TRUNCATE the table, and finally, re-enable the constraints with SET FOREIGN_KEY_CHECKS = 1;. This sequence ensures that tables are properly prepared for data generation without constraint violations.
2 Tables: The use of sequence models is confined to two tables to enhance synthetic data utility.
Resource Consumption: Due to its resource-intensive nature, this feature might decelerate your data generation process. It's advisable to lessen your input data or tweak the sequence model parameters to economize time and resources.
These guidelines aim to optimize your experience with Syntho.