Prepare your sequence data
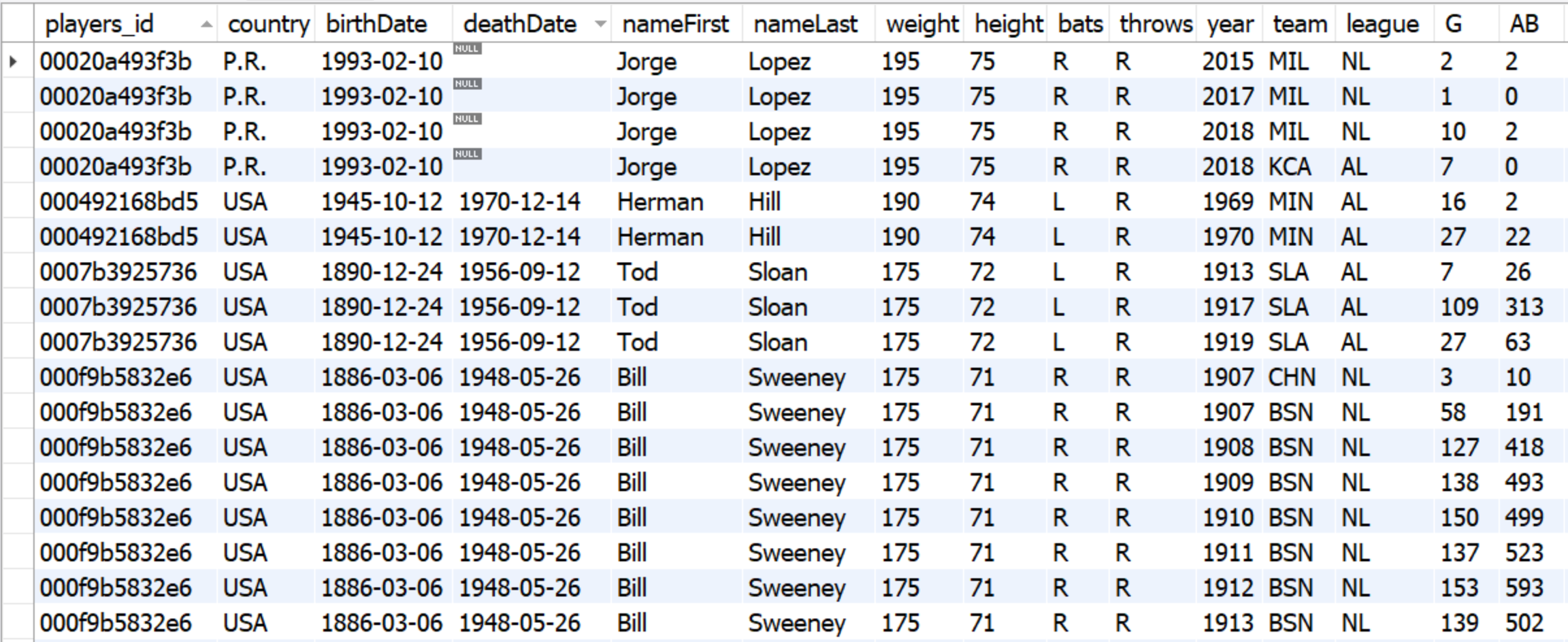
1. Split single sequential datasets into entity and linked tables
How to Split Data into Entity and Events
Entity Table
Linked Table
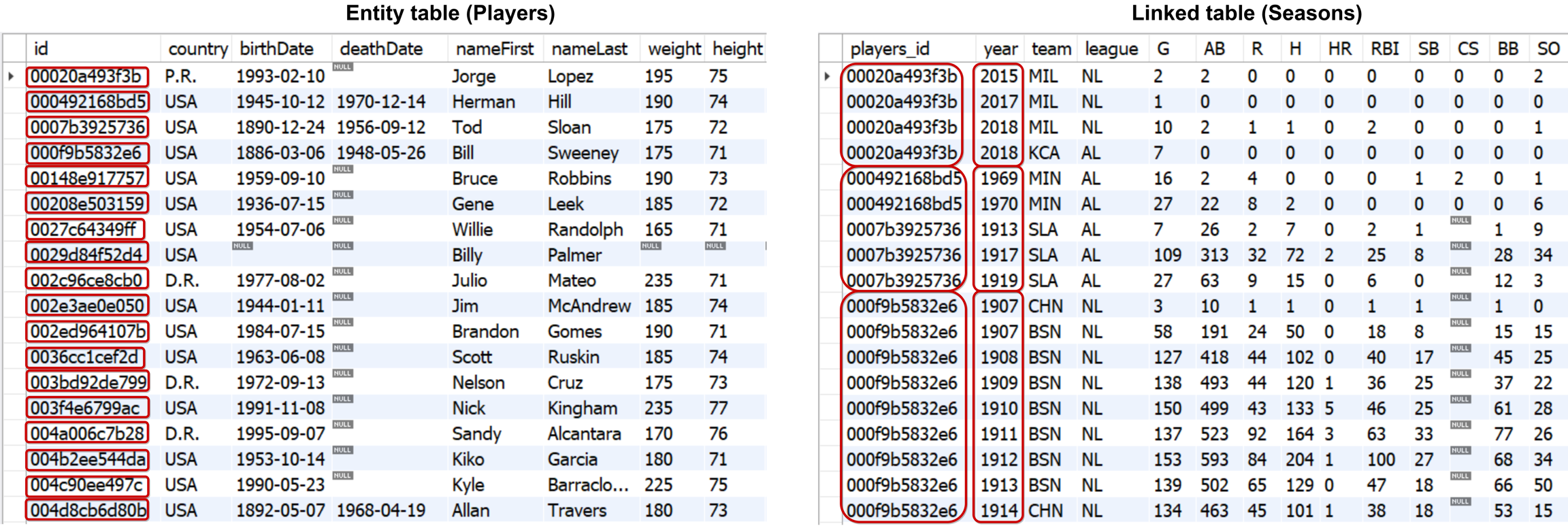
2. Transfer all static data to the entity table
Was this helpful?