Consistent mapping
Consistent mapping allows you to generate the same mock data values for a given set of original data values every time the mocker is applied. This feature can extend across various database types, allowing for consistent results. It is especially helpful when you need to consistently generate the same mock values based on the same input values, e.g. for testing or demonstration purposes.
Applicable generators
Consistent mapping can be applied to the following generators:
Mockers: Enable consistent mapping by selecting "Mocker" as the generation method in the column settings.
Mask: Consistent mapping can be utilized to ensure masked values remain consistent across multiple applications.
Hash: Consistent mapping is inherently enabled for the Hash generator, ensuring that the same input always results in the same hashed output.
Enable consistent mapping
To enable consistent mapping, open column configurations by clicking the column settings for the selected table. Please see below to find how to open the window.

Alternatively, clicking the “Configure” button after a PII scan also opens the column settings window.
After opening column settings window, click on the box next to the “Consistent Mapping” to enable consistent mapping with mocker. Keep in mind that you have to select “Mocker”, "Mask" or "Hash" as “Generation Method”.

Advantages of consistent mapping
Linking data: Even if your database doesn't force certain rules on how data is connected (like making sure email addresses match up), consistency lets you match things together anyway. For example, you can mock last names to keep them private but still link related columns.
Preserving distributions: If you have a list of different items, like 20 job titles in a column, and you want to mix them up without losing the overall distributions (still around 20 job titles), consistency is your friend. It keeps the distributions about the same.
However, remember that while consistency keeps the variety, it might not keep every item unique. The variety won't grow, but it could change slightly. If you need each item to match one-to-one to a new unique value, you will have to make the mocker unique.
Matching data across systems: If you're dealing with data spread out over different databases, like names in one place and email addresses in another, consistency helps you keep the names the same everywhere, even after making them private. This way, everything is still matched up correctly without sharing private information.
Consistent mapping example
Assume we have a table where the first name “Mavis612” appears twice. If you enable consistent mapping, both of these will be mapped to the same name, consistently, across the tables. See the illustrations below from MySQL tables where mockers with consistent mapping map the name “Mavis612” to “Jillian”. Please note that other names can also be mapped to Jillian. Consistent mapping does not suggest that only and only “Mavis612” will be replaced with “Jillian”.
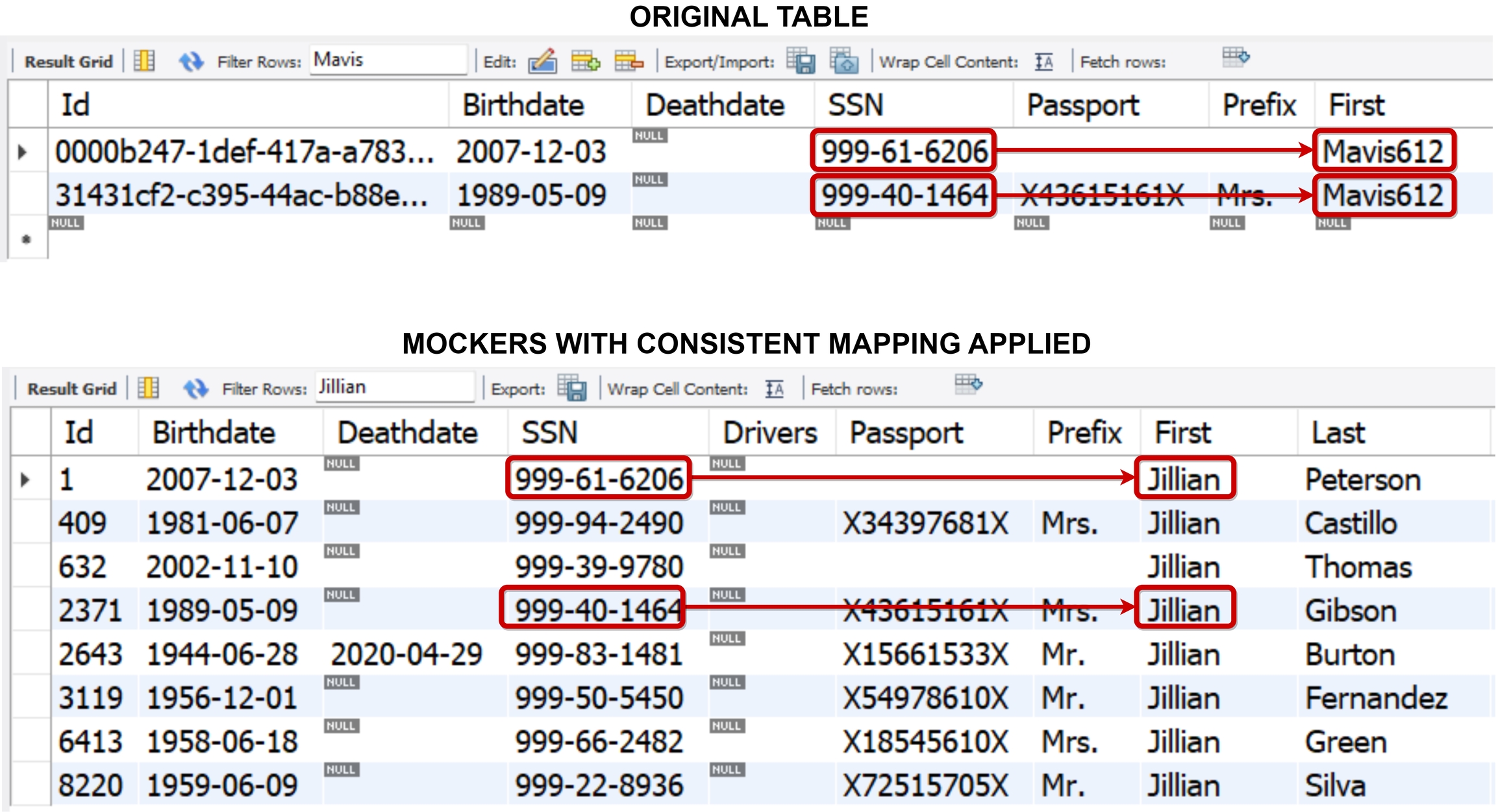
Understanding consistent mapping
Consistent mapping equals predictability: If you feed the same data into a mocker with consistent mapping enabled, you'll always get the same result. It's like using the same recipe every time to bake a cake; the outcome is predictable.
Uniqueness not guaranteed: Just because the process is consistent doesn't mean every different piece of data will come out differently. Two distinct inputs might lead to the same output. Think of it as different ingredients sometimes making a cake taste similar.
Privacy implications
No mappings stored: The Syntho platform uses a seed algorithm, which means it doesn't store any information about the transformation of input to output values. So, you can see "Karl" appears 10 times, but not that "Karl" was originally "Immanuel." Also, you may change how input values are mapped to output values.
Reduced privacy: Using consistent mapping might reveal some information, like how often certain data appears. For example, if "Karl" shows up 10 times, that pattern stays the same after the data is processed.
How consistency works across databases
Whole database application: Consistency applies across your entire database, not just within a single table. If you use consistent mapping for names in both a Customers and an Employees table, the same original name will always be updated to the same new name across both tables.
Not automatically across multiple jobs: By default, if you generate data more than once, consistency is automatically carried over from one generation job to the next. In case you don't want this, and you want to change consistency over jobs, you can set a different seed value. You can do this by going to the Workspace Default Settings, by selecting CTRL + ALT + SHIFT + 0, and update the seed_value to another integer value.
In short, consistency in data generation helps make sure your data behaves predictably, while also addressing the balance between maintaining useful patterns and protecting privacy.
Seed
The consistent mapping scheme is based on a defined seed value. For example, if seed=1 and consistency mapping is enabled for an Address generator, the same input address (e.g., "123 Main Street") will consistently map to the same output (e.g., "456 Elm Avenue"). If, after a period of using this consistent mapping scheme, the user decides to switch to a new seed (e.g., seed=2) for security reasons, the mapping will change. For instance, "123 Main Street" might then map to "789 Oak Drive" instead.
The seed value for a workspace can be changed under the Workspace default settings.
Ordering and indexing considerations
To ensure accurate ordering, it is essential for the application to have either an index or a primary key in the source table. In the absence of these, the application defaults to sorting based on the first column of the table. However, if the first column contains duplicate values, the ordering cannot be guaranteed, as it relies on the database's sorting algorithm to handle duplicate values. Adding an index to the source table will resolve this issue.
Column set for "ORDER BY" clause
In the Table Settings panel, a new dropdown field allows users to specify which columns should be used in the "ORDER BY" clause. This feature enables users to define a set of columns that ensure the uniqueness of the returned results for a given table. By selecting the appropriate columns, users can achieve deterministic ordering even in the absence of primary keys or indexes.
Order By Dropdown: Located in the Table Settings panel on the right side of the Table/Job Configuration screen, this dropdown lets users choose the columns for the "ORDER BY" clause.
Limitations
Consistent mapping does not guarantee consistency for generated data under different Syntho platform versions, or when deployed on different OSes (e.g., Windows vs Linux), or CPU architectures (e.g., x86 vs ARM).
Last updated
Was this helpful?